







編輯室
臺大電機系專題演講
時 間:102年5月22日下午3:30-5:20
地 點:博理館101演講廳
主持人:李學智教授
主講人:廖文豪副教授 / 國立台北商業技術學院資管系
‧前言
漢字解密地圖又可稱為漢字衍生關係圖或漢字樹,它以系統化的方式呈現文字的衍生脈絡,是解密漢字符號的有力工具。透過它,使用者不僅可以認識每一個漢字符號所代表的意義,也可以更進一步理解每個漢字背後所隱藏的古代文明。自從漢朝以隸書體代替古體字以後,許多甲骨文、金文所代表的圖像意義大幅消失,以至於無緣見識到甲骨文及金文的文字學權威東漢許慎,在編寫說文解字時產生不少錯謬。兩千多年來,華人天天讀漢字,卻多半不知它的構字意義,而漢字解密地圖有系統地解開華人長久以來的文字疑惑。為了解開兩千年來的文字之謎,廖教授憑藉資訊科技專長以及十餘年來研究古字體之熱忱,廣泛蒐集所有古字符號以進行比對分析,最後確認出每一個古字符號所代表的意義,進而建構出漢字解密地圖,於是出版了廣受矚目的漢字樹叢書。
主持人李學智教授特別介紹今日的演講者廖文豪副教授,目前任教於國立台北商業技術學院資管系,他同時也身兼該校的圖書館館長,並曾擔任過該校的計算機中心主任,其專長為資料庫的管理系統、資料模型的建構與分析、計算機結構。而對於漢字這麼獨特的研究,其實一般認為應該是中文系相關學者的專利,不過廖教授其實是我們台大電機系的學長,他依據他對漢字的興趣以及他在電腦方面的專業知識,對許多的漢字做了一些不同的解構,並加以整理得到了它們發展的脈絡與衍生地圖,整理成所謂的漢字樹。今天他要依據自己在資料庫方面的專業知識所整理出來的漢字地圖,來向各位娓娓道來漢字是如何創造與衍生的。
‧漢字樹的由來
廖教授一開始表示很榮幸能跟各位學弟妹們分享他研究漢字的一點點心得。在他所任教的北商有位外籍老師曾經提到他有十幾位朋友,跑到中國大陸去學中文,只學三個月左右就全跑回來了,他們覺得學中文太無聊,一筆一畫都不知道意思,卻要把它們硬背起來,這樣對一個成年人來說,實在是太痛苦,一輩子都很難學會。很多外國人會講流利的中文,但大都不會寫。如果能突破這點,勢必有助於漢字在國際間的推廣。
使用資訊工具來研究及整理古漢字是非常有利的,除了可以將漢字進行統整分析,還可以藉著它來建構出極為系統化的架構,而這在過去是不易達成的。漢字樹就是藉著資訊工具將漢字有系統架構起來的成果。漢字樹原本叫做漢字解密地圖,不過遠流出版社擔心有些讀者會看不懂,由於漢字衍生地圖看起來像是樹狀結構,所以就改做漢字樹。
‧從闖關遊戲中了解漢字衍生
為了增加趣味性,教授藉著漢字猜謎的闖關遊戲讓大家來體會一下漢字的衍生,請大家猜一猜每個象形字所代表的現代漢字。第一關是有關房子的衍生,它的衍生過程好像是孩童畫圖。先畫一個房子的輪廓 ![]() (宀),再畫一個門,就成了一棟最簡單的房子
(宀),再畫一個門,就成了一棟最簡單的房子![]() (向),商周的人蓋房子都是坐北朝南,大門一打開來便是南方,於是這個字便引申出方向的意涵。接著,為了讓房子看起來更宏偉,於是在原有屋頂上頭再添加一層華麗屋頂
(向),商周的人蓋房子都是坐北朝南,大門一打開來便是南方,於是這個字便引申出方向的意涵。接著,為了讓房子看起來更宏偉,於是在原有屋頂上頭再添加一層華麗屋頂 ![]() (尚),在古代,屋頂的等級限制十分嚴格。天子居住的殿堂,其屋頂構形採用從最高等級的重簷廡殿,紫禁城太和殿、故宮博物院也是採用這種屋頂構形。接下來,再以夯土台當地基墊高房子,就成了
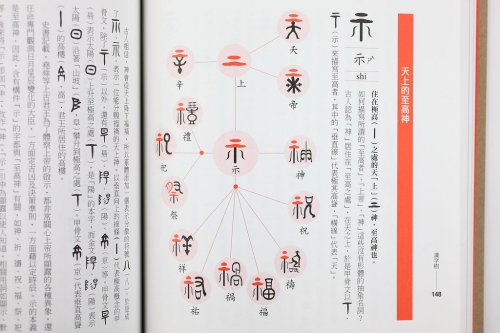
(尚),在古代,屋頂的等級限制十分嚴格。天子居住的殿堂,其屋頂構形採用從最高等級的重簷廡殿,紫禁城太和殿、故宮博物院也是採用這種屋頂構形。接下來,再以夯土台當地基墊高房子,就成了 ![]() (堂)。在周朝,殿堂台基的高度是有嚴格規定的,地位高的人才能居住在台基較高的房子。《禮記》記載:「天子之堂九尺,諸侯七尺,大夫五尺,士三尺。」以前我們講的寶蓋頭「宀」,許多人都不知道它代表房子,以為跟頭或蓋子有關,其實所有的「宀」都跟房子有關,如宅、室、寮、宇等上百個字都是,從投影片中「宀」的衍生圖來看,「宀®向®尚®堂」只是眾多衍生路徑當中的一條而已。
(堂)。在周朝,殿堂台基的高度是有嚴格規定的,地位高的人才能居住在台基較高的房子。《禮記》記載:「天子之堂九尺,諸侯七尺,大夫五尺,士三尺。」以前我們講的寶蓋頭「宀」,許多人都不知道它代表房子,以為跟頭或蓋子有關,其實所有的「宀」都跟房子有關,如宅、室、寮、宇等上百個字都是,從投影片中「宀」的衍生圖來看,「宀®向®尚®堂」只是眾多衍生路徑當中的一條而已。
過去我們學漢字,卻連基本符號的意義都不甚了解。在他小學時,以為雙人旁「彳」跟人有關係,但那時候問老師時並沒有得到一個清楚的答案,一直到他自己研究漢字以後才發現雙人旁其實是指一條馬路。比如說「行」的古字「╬」代表四通八達的馬路,若把右半邊省略掉,就變成了「彳」,就是後人所稱的雙人旁。由此可知,我們一定要認識基本的漢字符號,才不會被誤導,才能真正認識漢字的精髓。
第二關的衍生關係也很有趣。如何描寫一個人的舌頭呢?舌頭自口而出,可以上下左右擺動,擺動的時候還會有口水噴濺,於是古人造了「舌」。「舌」的甲骨文![]() 描寫從口裡吐出一條會擺動之物(Y字形舌頭),周圍之小點表示口水。舌是可幫助說話、分辨味道的器官。「舌」的衍生主幹為
描寫從口裡吐出一條會擺動之物(Y字形舌頭),周圍之小點表示口水。舌是可幫助說話、分辨味道的器官。「舌」的衍生主幹為 ![]() →
→ ![]() →
→ ![]() →
→![]() 。首先,
。首先,![]() 伸出一條會擺動之物,於是就衍生出
伸出一條會擺動之物,於是就衍生出 ![]() (舌);接著,舌頭一擺動,就能產生言語,言(
(舌);接著,舌頭一擺動,就能產生言語,言(![]() )表示在「舌」(
)表示在「舌」(![]() )之「上」(
)之「上」( ![]() );古人進一步發現,當人口中含著樹葉或管子等物,便能發出美妙樂音,於是他又在
);古人進一步發現,當人口中含著樹葉或管子等物,便能發出美妙樂音,於是他又在 ![]() (言)內再添加一筆畫,音(
(言)內再添加一筆畫,音(![]() )表示口含一物所發出之美妙「言」語。接著,廖教授展示「口」的衍生圖並解釋其中一些有趣的漢字。
)表示口含一物所發出之美妙「言」語。接著,廖教授展示「口」的衍生圖並解釋其中一些有趣的漢字。
第三關漢字猜謎是有關人的衍生。漢字的造字很有系統,由簡至繁,由具象到抽象,例如「繁」是由 ![]() →
→![]() →
→ ![]() →
→ ![]() →
→![]() →
→ ![]() ,先有一個不分性別的
,先有一個不分性別的 ![]() (人)。這個人跪坐下來,「雙手交垂」便衍生出「女」(
(人)。這個人跪坐下來,「雙手交垂」便衍生出「女」(![]() ),一個端莊賢淑的女子。如果在「女」字的胸前添加「兩點」之後,就又衍生出具有「哺乳」能力的「母」(
),一個端莊賢淑的女子。如果在「女」字的胸前添加「兩點」之後,就又衍生出具有「哺乳」能力的「母」( ![]() )親;若在母親的頭上再添加「一根根頭髮」,就衍生出「每」(
)親;若在母親的頭上再添加「一根根頭髮」,就衍生出「每」( ![]() ),藉此引申出每一根、每一滴等意涵。如果在「每」的旁邊添加一隻持梳子的「手」,就衍生出「敏」(
),藉此引申出每一根、每一滴等意涵。如果在「每」的旁邊添加一隻持梳子的「手」,就衍生出「敏」(![]() ),意表一隻快速打理滿頭亂髮的手。最後在「敏」底下加上一條「髮辮」(
),意表一隻快速打理滿頭亂髮的手。最後在「敏」底下加上一條「髮辮」( ![]() ),就衍生出「繁」(
),就衍生出「繁」( ![]() ),因此由編織髮辮引申出「繁複、繁瑣」等意涵。
),因此由編織髮辮引申出「繁複、繁瑣」等意涵。
從以上的衍生關係可以看出古人造字有一些衍生規則:由簡單筆劃逐步添加構件而衍生成繁複筆劃的字;其次,是從具象的文字,如人、女、母,逐步進入愈來愈抽象的文字,如每、敏(敏捷)、繁(繁複)。許多字看似雜亂無章,但若是能抽絲剝繭找出字與字之間的衍生關係及演化關係,便能解開漢字構字的奧秘。所謂的「衍生關係」是由一個字衍生出另一個字,而「演化關係」是指同一個字,由甲骨文、金文、篆體,一直演變到現代字體的過程。若是能掌握漢字的衍生路徑以及漢字的演化順序,就能建構出完整的漢字系統。
經由上述幾關漢字衍生猜謎遊戲,廖教授主要是想讓大家了解,我們能夠根據一套有系統的架構,透過電腦把許多有關聯的漢字符號都找出來,如此便能破解每個漢字符號背後的意義。在他剛開始做研究時便遭遇一些困境,每個學者對於每一個符號的解釋都不太一樣,非常地不一致。所幸,像是大海撈針的幾十萬個符號裏,藉著資訊工具的彙整分析,還是能有系統找出古漢字彼此之間的關聯性。
‧漢字解密樂無窮
而在讓同學們透過闖關的方式了解漢字的衍生關係後,廖教授接下來準備另一份投影片,讓大家體會漢字解密就像破解命案一樣,充滿著懸疑與趣味性。破解漢字必須設定相關的檢驗原則,否則會流於自說自話,缺乏公信力。廖教授自訂五項檢驗原則,例如,必須符合甲骨文、金文構型,必須有先秦典籍為依據,其次,對每一個漢字符號的詮釋必須能套用在所有含有此符號的漢字上,除此之外,還必須能據此合理詮釋所有引申意義。
例如「方」是一個很常用的字,但構字起源眾說紛紜,東漢許慎的《說文解字》認為「方」是兩艘併攏的船,但從甲骨文、金文等構形卻是怎麼看都不像;近代有學者認為「方」是挖土的耒插(圓鍬),但也無法自圓其說;也有學者認為是一個人在挑扁擔;還有人認為方是畫方型的工具,卻無法解釋如何操作。自許慎以來,「方」困擾了不知多少的古今學者。什麼是「方」?翻閱先秦史書,再對照甲骨文、金文及篆體,可以清楚發現,「方」指的就是「國境外的人民」,這樣的詮釋使得各種包含「方」的漢字及史書記載都變得合理。周朝典籍中記載著,商周人稱邊境外的民族為方,例如,當時北方民族有鬼方、土方,西方有羌方、東方有人方。所以,「方」就是指鄰國人,方的甲骨文 ![]() 、
、 ![]() 在「人」之上添加「一橫畫」,表示邊境上的人民。
在「人」之上添加「一橫畫」,表示邊境上的人民。
為了進一步驗證,廖教授將所有含有方的古字彙整起來,主要有「旁、邊、防、放、敖」等,赫然發現這些字都與鄰國有關,「旁」代表四圍邊境的鄰國人,「邊」代表鄰國人從邊境進入本國,「防」代表阻擋鄰國人的城牆,「放」代表流放到鄰國,「敖」代表到鄰國出遊。
另外,就引申意義的驗證來看,商周時代,各國的國土講究「四方」,唯有四四方方的領土才算是完整的國土。《周禮》記載:「方千里曰王畿」,國土的中央是君王所居住的王城,是一塊占地一千平方公里的方正土地,而再往外一層層擴展的土地也都是四方形。方的本義為國境外的一群人民,以此來檢視它以下幾個引申義也都是吻合的。
1 方向或方位:所謂的「東方」就是指位於「東邊的方國」,「西方」就是指位於「西邊的方國」,因此後人以東方、西方等代表方向或方位;
2 某一邊:由於方國相當多,而且國名常有更變,當描述國與國之間所發生的事件時,為了簡化敘述,就簡化以代號來稱呼了,如敵方、友方、甲方、乙方等;
3 四邊對稱的形狀:殷商人稱「四境鄰國所圍之地」為「四方」,相關用詞如正方、長方等。
除了用於破解漢字以外,廖教授說漢字衍生圖也簡化了六書,使人更易理解構字意義。大家都知道,自古以來,大家都以六書來講解漢字,但其中的轉注、假借就連中文系畢業生都難以說清楚,可見六書教學法其實是非常複雜難懂的。事實上,每個漢字符號不外就是形、音、義而已,像「方」這個符號到底代表聲音還是意義,我們可以清楚地從衍生圖上看到,圖中的實線代表跟意義有關,虛線代表跟聲音有關。例如,「旁、邊、防」等裏頭的方是代表意義,屬於義符;而「芳、肪」等裏頭的方是代表聲音,屬於聲符。透過義符與聲符的辨別,大量簡化學習上的困擾。
接下來廖教授繼續為大家說明解密地圖在歷史考證的應用。頭一個歷史謎題是,大禹到底存不存在?「禹」代表什麼意義呢?《說文解字》說「禹」是一條蛇,因為它中間有個「虫」,而虫就是蛇。知名史學家顧頡剛據此提出「禹」的構字本義既然是一條蛇龍,所以大禹是個虛構人物,根本不存在。此外,史學家楊寬說,大禹是由「虫」、「九」兩符號組合而成,代表一條勾龍。他進一步說,古籍記載勾龍的父親是共工,既然勾龍就是大禹,而大禹的父親又是鯀,因此他的結論是「共工就是鯀」。雖然這項推論很有意思,但其實充滿矛盾的。首先,《孟子》說大禹是「驅蛇龍,治水患」的人,如果他自己是蛇龍,那怎麼會去趕蛇龍呢?此外,史書記載「大禹伐共工」,如果共工是禹的父親,那大禹攻打父親不就成了大逆不道的不孝子嗎?所以這樣的推論顯然沒有考證清楚。另外,故宮博物院的研究員楚戈在《龍史》一書中說,金文「禹」像是兩條蛇龍交纏在一起,所以他推論「禹」代表兩條蛇在交配,因此引申出「禹」有淫亂的意思。無獨有偶,大陸名嘴更在電視上宣稱大禹有外遇,否則他三過家門而不入是很不正常的。
「禹」這個字到底代表甚麼?從金文及篆體來看,的確是由「虫、九」所構成,虫代表蛇,但九代表什麼呢?從九的衍生圖來看,九其實代表一條伸長的手臂,所有包含九的漢字都與伸長的手臂有關。例如「仇」代表伸長手臂去抓的仇人,意味著無論仇人逃到天涯海角都要把他擒拿,又如「究」代表伸長手臂去洞穴中摸索,探究也,而「萬」則是伸長手臂除去蠍子。既然九代表伸長的手臂,那麼,禹就代表抓蛇龍的人,這樣的禹與史書上所說驅蛇龍治洪水就完全吻合了。為了進一步舉證,廖教授將虫及九的衍生圖作了一番解釋,如「強」代表拉大弓射大蛇,引證了古籍中劉裕、后羿射大蛇的典故,「閩」代表「蛇門」境內,意指古代越國境內,同時也引證了《吳越春秋》的「蛇門」典故。
再來看看「龍」的演化歷史,甲骨文的「龍」![]() 像是一條張開大嘴的蛇,不少專家考證,古代的原始龍就是大蟒蛇之類的生物,但為何在金文、篆體裡卻在大蛇之上添加一個「辛」的符號呢?由辛的衍生圖來看,含有此符號的漢字都與罪犯有關,因為「辛」就代表逆天之人。既然如此,龍不就意味著是一條逆天的大蛇嗎?原來,古代發生大水患,被認為是逆天之龍所造成的,一直到大禹驅走蛇龍,水患才平息。《孟子》說:「當堯之時,水逆行,氾濫於中國。蛇龍居之,民無所定。」《論衡》也說:「洪水滔天,蛇龍為害,堯使禹治水,驅蛇龍,水治東流。」黃河龍門是大禹驅趕蛇龍的遺跡,長江三峽的龍脊石是大禹斬蛇龍的遺跡。古字也可證實相關記載,如甲骨文
像是一條張開大嘴的蛇,不少專家考證,古代的原始龍就是大蟒蛇之類的生物,但為何在金文、篆體裡卻在大蛇之上添加一個「辛」的符號呢?由辛的衍生圖來看,含有此符號的漢字都與罪犯有關,因為「辛」就代表逆天之人。既然如此,龍不就意味著是一條逆天的大蛇嗎?原來,古代發生大水患,被認為是逆天之龍所造成的,一直到大禹驅走蛇龍,水患才平息。《孟子》說:「當堯之時,水逆行,氾濫於中國。蛇龍居之,民無所定。」《論衡》也說:「洪水滔天,蛇龍為害,堯使禹治水,驅蛇龍,水治東流。」黃河龍門是大禹驅趕蛇龍的遺跡,長江三峽的龍脊石是大禹斬蛇龍的遺跡。古字也可證實相關記載,如甲骨文![]() 表示龍在吐水,
表示龍在吐水,![]() 、
、![]() 代表雙手抓龍。廖教授也同時以虹、寵、龐、龔等字及有趣典故加以引證。龍為何後來被認為是好的呢?廖教授認為轉捩點在劉邦,劉邦是歷史上第一個平民皇帝,他利用人民對龍的迷信與恐懼,捏造自己是一條紅龍的許多事蹟,包含母親遭蛟龍性侵生下自己,將自己斬白蛇事蹟說成紅龍斬殺白龍,妻子呂后也編造有紅龍盤旋在劉邦頭頂等等,劉邦當上皇帝後開始身穿龍袍,凡此種種,於是,惡龍從此翻身為好龍。
代表雙手抓龍。廖教授也同時以虹、寵、龐、龔等字及有趣典故加以引證。龍為何後來被認為是好的呢?廖教授認為轉捩點在劉邦,劉邦是歷史上第一個平民皇帝,他利用人民對龍的迷信與恐懼,捏造自己是一條紅龍的許多事蹟,包含母親遭蛟龍性侵生下自己,將自己斬白蛇事蹟說成紅龍斬殺白龍,妻子呂后也編造有紅龍盤旋在劉邦頭頂等等,劉邦當上皇帝後開始身穿龍袍,凡此種種,於是,惡龍從此翻身為好龍。
最後,廖教授讓大家玩一場漢字解密遊戲,「冉」這個古字到底是描寫甚麼呢?有學者說是魚,也有說是臉上的毛髮,有人說是龜、蛙等,但答案是什麼呢?我們先從眾多包含此符號的甲骨文來找線索,甲骨文顯示,冉會在陸地上走路,有人在追冉,有人抓冉來火烤,有人坐船去抓冉,冉還可以在市場上秤重販售,到底冉是什麼樣的生物呢?透過實物圖像、字形辯證、古籍引證、字義引申及衍生關係等檢驗後,廖教授提出鱉甲說,相當有趣!
‧整理漢字,引經據典
在講述完兩個主題後,同學們的發問也十分熱烈,廖教授也耐心的一一解說。像是有同學便好奇,甲骨文的字這麼少,那後來的漢字是怎樣整理出來的?廖教授答道:「甲骨文雖然字不多(約4000字),但所有的部首或基本符號都已經出現了,以後出現的許許多多漢字都是由這些基本符號所拚出來的。」另外也有同學提出質疑,這些漢字有些解釋聽起來很有道理,但有些卻好像是自圓其說,是不是研究這個領域的人都是在自圓其說呢?廖教授解釋道,的確在很多人研究漢字,有時候並沒有考慮得很清楚,但是他所解的漢字都會遵守五大項檢驗原則,如符合考古證據(如甲骨文字形或古文物)、符號詮釋及衍生關係的完整一致性、先秦典籍引證、字義引申的合理性等。除了邏輯上的正確性外,一定要在古文物或古籍中有證據,而這種理性辯證的態度應該也是身為理工人的一個特質吧!